
לפני כחודשיים ישבתי עם צוות מוצר בסטארט-אפ SaaS שבנה כלי AI לניהול משימות. הם הראו לי את המוצר והדבר הראשון שראיתי היה מסך עם תיבת טקסט ריקה וכיתוב "Ask me anything". שאלתי את המשתמשים שלהם מה הם מרגישים כשהם פותחים את הכלי בפעם הראשונה, והתשובה הכי נפוצה הייתה: "אני לא יודע מאיפה להתחיל." מוצר עם טכנולוגיה מצוינת, אבל חוויית משתמש שלא נתנה כיוון.
בשנתיים האחרונות יצא לי לעצב מוצרי AI, מכלי SaaS ועד מוצרים פנימיים בחברות גדולות. בהתחלה כל פרויקט הרגיש שונה לגמרי, אבל לאט לאט התחלתי לראות דפוסים שחוזרים על עצמם שוב ושוב. בדקתי כלים כמו Cursor, Perplexity, Lovable, Figma AI, Make, Notion AI, ומוצרי SaaS שעיצבתי בעצמי. תחומים שונים, קהלים שונים, אבל אותן שאלות בדיוק.
אני רוצה לשתף אתכם בשישה דפוסים שזיהיתי שיכולים לעזור לכם לעצב מוצרים מבוססי AI. הדפוסים האלה יעזרו לכם להבין איך בונים אינטראקציה עם AI שמשתמשים באמת יכולים לסמוך עליה. לא בגלל שהטכנולוגיה מושלמת, אלא בגלל שהממשק נותן להם שליטה והבנה של מה קורה מאחורי הקלעים.
1. תיבה ריקה זה לא מספיק (States Empty Guided)
פותחים כלי AI חדש בפעם הראשונה. יש תיבת טקסט, והיא ריקה. אנשים כבר יודעים לכתוב לצ'אט, ChatGPT לימד את זה את כולנו. אבל שימו לב להבדל: כשמגיעים לכלי ספציפי, לרוב לא יודעים מה הוא יכול לעשות בדיוק, מה הגבולות שלו, ואיפה הוא באמת מוסיף ערך לעומת כלי כללי.
ב-Lovable, ה-placeholder כבר מספר משהו ספציפי. לא "anything me Ask", אלא הצעה קונקרטית שמלמדת מה הכלי עושה ומה אפשר לצפות ממנו. ב-Make Figma הלכו צעד נוסף: יש כפתורים שמתחילים פעולה מיידית, לא רק הצעות, אלא נקודות כניסה שמפחיתות את החיכוך בין "אני רוצה לנסות" ל"אני מתחיל לעבוד." ב-ChatGPT תראו גישה שלישית: Dropdown שנותן למשתמש להבין את האפשרויות של מה שאפשר לעשות. וב-AI Notion, שילבו את ה-AI בתוך תפריט commands slash שכבר מוכר למשתמשים, כלומר במקום ללמוד ממשק חדש, המשתמש משתמש בדפוס שהוא כבר מכיר ומגלה יכולות AI בתוכו.
Lovable — Guided Empty State
Figma Make — Clickable Starting Points
העצה שלי: תנו למשתמשים נקודת התחלה ברורה. ככל שהמוצר ספציפי יותר, ההנחיה צריכה להיות יותר ממוקדת. אם המוצר שלכם עושה דבר אחד טוב, תראו את הדבר הזה כבר במסך הראשון. אם יש כמה יכולות, סדרו אותן לפי התרחישים הנפוצים ביותר.
2. להראות את החשיבה, לא רק את התוצאה (Thought of Chain ו-Processing Transparency)
יש כאן שני דברים שנראים דומים אבל שונים, וחשוב לי לחזור ולהדגיש את ההבדל כי הוא משפיע על איך אתם מתכננים את הממשק.
הראשון הוא Thought of Chain: ה-AI מראה את שלבי החשיבה שלו בזמן אמת, לפני שמגיע לתשובה. "ראשית בדקתי X, אחר כך שקלתי Y, ולכן הגעתי ל-Z. "ב-Cursor אפשר לראות את זה בפועל, שלב אחרי שלב, לפני שהקוד מוצע.
זו לא רק שקיפות, זה מאפשר למפתח לזהות בדיוק איפה ה-AI הלך לכיוון שגוי ולתקן אותו מוקדם, לפני שמשקיעים זמן בפתרון לא נכון. ב-Claude הוסיפו thinking extended, שמראה את תהליך החשיבה המלא, כולל ספקות ושיקולים. ב-Perplexity זה קצת שונה: החשיבה והמחקר קורים ביחד, רואים את
ה-AI סורק מקורות ומעריך אותם בזמן אמת, כך שתהליך החשיבה הוא גם תהליך האיסוף עצמו.
Perplexity — Chain of Thought Reasoning
השני הוא Processing Transparency ברמה רחבה יותר. ב-Claude Codeרואים בזמן אמת אילו קבצים
נקראים ואילו פקודות מורצות. וב-Notion AI, כשמבקשים סיכום של מסמך, רואים אנימציה שמראה שה-AI "קורא" את הטקסט. זה נראה כמו פרט קטן, אבל זו בדיוק הנקודה: כשה-AI מבצע פעולות בעולם האמיתי, לא רק כותב טקסט, השקיפות הזו הופכת להיות קריטית.

שני הדפוסים פותרים את אותה בעיה בסיסית: ה-AI לא צריך להיות קופסה שחורה.
כמה דרכים לשלב את זה בתכנון:
- אם המוצר שלכם עושה חיפוש או מסיק מסקנות, הראו את מקורות המידע ולא רק את התוצאה.
- אם יש תהליך חשיבה (reasoning), חשפו אותו גם אם הוא ארוך, משתמשים יכולים לדלג עליו אבל הם צריכים את האופציה.
- אם ה-AI מבצע פעולות (כלים אג'נטיים), הראו כל פעולה לפני שהיא מתבצעת ואחריה.
3. שליטה לפני ואחרי (Draft-First, Iterate, Undo)
לפני כמה חודשים ראיתי כלי AI בחברת B2B שמתזמן פגישות אוטומטית. שולח מיילים בלי לשאול, מפרסם תוכן, מעביר משימות. הרעיון היה לחסוך זמן, אבל אחרי טעות אחת, אחת בלבד, שבה נשלח מייל לא נכון ללקוח, הצוות הפסיק להשתמש. זו לא בעיה טכנית, זו בעיה של עיצוב. כשה-AI פועל בלי לשאול, המשתמש
מאבד שליטה. וכשמשתמשים מרגישים שאיבדו שליטה, הם מפסיקים לסמוך.
שליטה קיימת בשני שלבים:
לפני שה-AI פועל: ב- GitHub Copilot, קוד מוצע מופיע באפור, Tab פירושו "כן" ו-Esc פירושו "לא". שליטה מלאה בלי לשבור את הזרימה. ב-Google docs הטקסט שה-AI מציע מופיע בצבע אחר עם כפתורי Discard/Accept. ה-AI מציע, האדם מחליט. ככל שכלים הפכו לאג'נטיים יותר, הדפוס התפתח: במקום לאשר
כל שלב, חלק מהכלים נותנים לבחור מראש את רמת האוטונומיה. ב-Cursor למשל, Plan Mode ,Ask Mode ו-Agent Mode הם שלוש רמות שונות של שליטה, והמשתמש בוחר לפי ההקשר.
שלוש שאלות שעוזרות להחליט מתי צריך אישור:
- האם הפעולה ניתנת לביטול? )אם לא, חובה לשאול(
- האם היא משפיעה על גורמים חיצוניים? )שליחה, פרסום, מחיקה(
- האם היא עלולה לגרום נזק אם תהיה שגויה?
אחרי שה-AI הציע יש שני סוגים של שליטה שכדאי להבחין ביניהם.
הראשון הוא Fine tuning: ב-Midjourney, אחרי שה-AI מייצר 4 אפשרויות, כפתורי V (וריאציה) ו-U(שדרוג) נותנים שליטה מדויקת על הכיוון, בלי לכתוב prompt מאפס. ב-AI Figma אפשר לבקש וריאציות על עיצוב שנוצר ולהשוות בין גרסאות זו לצד זו.
השני הוא undo, ורמה שונה לגמרי. זה לא לכוון את מה שה-AI עשה, אלא לחזור אחורה לפני שהוא עשה אותו.
ב-Lovable אפשר לחזור לכל גרסה קודמת של הפרויקט, כולל history git מלא. ב-AI Notion כל שינוי שה-AI עשה אפשר לבטל ב-Z+Cmd פשוט. אנשים מוכנים לנסות דברים חדשים כשהם יודעים שאפשר לחזור אחורה, וזו נקודה שמעצבים רבים לא נותנים לה מספיק משקל.
Lovable — Revert to Previous Version
Figma AI — Undo / Compare Options
4. חשיפה הדרגתית של יכולות (Disclosure Progressive)
מוצר AI לא צריך להראות את כל מה שהוא יודע לעשות ביום הראשון. בדיוק כמו שבמוצרי SaaS קלאסיים אנחנו משתמשים ב-progressive disclosure כדי לא להציף משתמשים חדשים, גם במוצרי AI הדפוס הזה קריטי, ואפילו יותר, כי היכולות של AI עלולות להרגיש אבסטרקטיות ומאיימות.
ב-Cursor, מפתח חדש מתחיל עם autocomplete בסיסי, שזה דפוס מוכר ולא מאיים. רק אחרי שמתרגלים, מתחילים לגלות את ה-Composer Mode שמאפשר לבנות פיצ'רים שלמים בשיחה, ואת Agent Mode שמריץ פקודות ומתקן שגיאות בעצמו. כל שלב נגיש רק אחרי שהקודם הפך לטבעי. ב-ChatGPT, custom instructions ו-memory הם פיצ'רים שמתגלים עם הזמן, לא בפתיחה הראשונה. וב-Canva, יכולות ה-AI (Magic Eraser, Magic Expand, Text to Image) מופיעות בהקשר הנכון: כשאתם עורכים תמונה, לא בדף הבית.
אנשים לא יודעים מה לעשות עם "אני יכול לעזור לך בהכל." הם יודעים בדיוק מה לעשות עם "רוצה שאעזור לך לנסח את המייל הזה?"
העצה שלי:
תתחילו עם יכולת אחת ברורה שנותנת ערך מיידי, ותחשפו את השאר בהדרגה לפי שימוש. תנו ל-AI לגדול עם המשתמש, לא לנחות עליו.
5. כמה אפשר לסמוך על התשובה (Confidence indicators)
ה-AI תמיד נשמע בטוח. זה אחד האתגרים הכי גדולים בעיצוב מוצרי AI: המשתמש לא יודע אם התשובה מבוססת על נתונים מוצקים או על ניחוש סטטיסטי. בשיחה חופשית זה לא תמיד בעיה, אבל בהחלטות שיש להן השלכות, כמו רפואה, כספים, או משפטים, זה הופך לקריטי.
שתי דרכים עיקריות לתת למשתמש את המידע הזה:
- שפה: "הנתונים מראים" משדר ביטחון גבוה. "נראה ש…" בינוני. "אני לא בטוח, אבל…" נמוך. פשוט, ולא דורש שום מרכיב UI נוסף.
- ציון מפורש: Grammarly נותן ציון לכל הצעה, אפשר לראות מיד כמה ה-AI בטוח בתיקון.

Tooltip — Indicator Confidence המציג את רמת הוודאות של ה-AI
הנקודה החשבוה: כשה-AI פחות בטוח, הוא צריך לפעול אחרת, לא רק לכתוב הערה קטנה בטקסט. השינוי צריך להיות ברור וויזואלי.
לא תמיד צריך את כל השלבים האלה. שיחה כללית? שפה מספיקה. החלטה קריטית (רפואה, כספים, משפטים)? ציון מפורש ואולי גם חסימה אוטומטית של פעולה עד לאישור אנושי. תשאלו את עצמכם: מה הנזק הפוטנציאלי אם ה-AI טועה כאן? התשובה תגיד לכם כמה אגרסיבי צריך להיות ה-confidence indicator.
6. כשזה לא עובד
כשה-AI לא יודע, עדיף "אין לי מספיק מידע כדי לענות בבטחה" מאשר תשובה לא מבוססת. לפני כמה שבועות בדקתי מוצר AI לשירות לקוחות שהמשיך לייצר תשובות גם כשלא היה לו מידע רלוונטי. הלקוחות הגיעו לנציג אנושי בכל מקרה, רק אחרי שהתעכבו ואיבדו סבלנות. עדיף היה להעביר מהרגע הראשון.
כשהמשתמש תקוע, כלים טובים מציעים כיוון. ב-Perplexity יש הצעות לחיפושים קשורים שנותנות מסלול המשך, כך שגם אם התשובה לא מושלמת, יש לאן להמשיך.
וכשגם ה-AI וגם המשתמש תקועים, צריך בן אדם. ב-Fin AI, המעבר לנציג קורה בתוך השיחה הטבעית. ה-AI לא מפנה לכפתור חיצוני, אלא מציע להמשיך עם אדם כשלב הגיוני בזרימת השיחה עצמה. במוצר AI שעיצבתי לחברת SaaS, הוספנו כפתור "Talk to support" בצד השיחה. אנשים השתמשו בו, לא הרבה, בערך 8% מהשיחות, אבל מספיק. וזה בדיוק מה שרצינו: רשת ביטחון שנותנת ביטחון גם כשלא משתמשים בה.
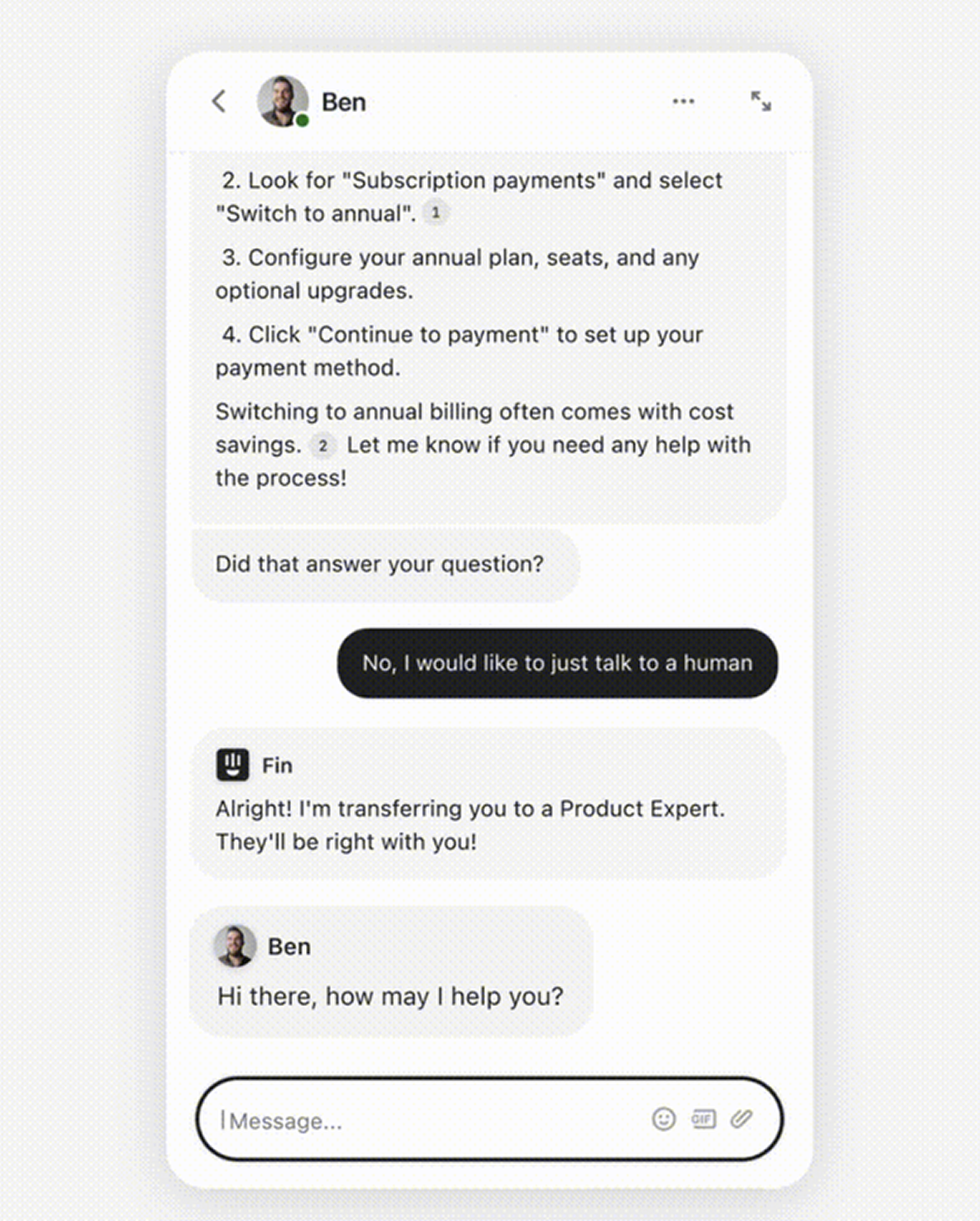
הרעיון המרכזי: כלי AI לא צריך להחליף בני אדם. הוא צריך לדעת מתי הוא לא מספיק, ולהעביר את השרביט בצורה נקייה. המשתמשים הכי נאמנים הם לא אלה שה-AI תמיד ענה להם נכון, אלא אלה שכשה-AI לא ידע, הוא אמר את זה בכנות.
אז מה עושים עם זה?
אלה לא כל הדפוסים שקיימים כמובן, אבל אלה 6 הדפוסים שחוזרים הכי הרבה במוצרים שכולנו מכירים. כולם עוזרים לבנות אמון בין המשתמש למוצר ה-AI, בעיקר על ידי שלושה דברים: שקיפות, שליטה, והכרה בכך שה-AI לא תמיד צודק.
אם אתם עובדים על מוצר AI, לא צריך ליישם הכל בבת אחת. התחילו מהשאלה: איפה משתמשים נושרים או נתקעים? ואז תנסו להבין אם זה קשור לשליטה, שקיפות, או ביטחון בתוצאה.
צ'קליסט מהיר לבדיקת מוצר AI
- מסך ראשון: האם משתמש חדש יודע מה לעשות? האם יש נקודת התחלה ברורה?
- שקיפות: האם המשתמש רואה מה ה-AI עושה ולמה?
- שליטה לפני: האם יש אישור לפני פעולות שלא ניתנות לביטול?
- שליטה אחרי: האם אפשר לערוך, לכוון מחדש, ולחזור אחורה?
- חשיפה הדרגתית: האם יכולות ה-AI מתגלות בהדרגה או מוצפות בבת אחת?
- ביטחון: האם המשתמש יודע כמה לסמוך על כל תשובה?
- כישלון: האם יש מסלול ברור כשה-AI לא יודע, כולל גישה לבן אדם?
העצה שלי: תעברו על הצ'קליסט הזה פעם בחודש, לא רק בתחילת הפרויקט. ככל שמשתמשים לומדים את הכלי שלכם ומצפים ממנו ליותר, הצרכים האלה משתנים.
כמו שאמר פעם Don Norman: "הטכנולוגיה הטובה ביותר היא כזו שנעלמת." במוצרי AI, זה אומר שה-AI הטוב ביותר הוא לא זה שעושה הכל לבד, אלא זה שעובד ביחד עם המשתמש בצורה שמרגישה טבעית.
מוזמנים לפנות בלינקדאין אם יש שאלות, או אם נתקלתם בדפוסים אחרים ששווה לשתף.
אהבתם את הפוסט? אולי תאהבו גם את עמוד הפייסבוק שלנו, אנחנו מעלים טיפים יומיים על נושאים שמרגשים אותנו.
משאבים:
• המדריך הכי מקיף לעיצוב מוצרי AI, עם דפוסים ודוגמאות מעשיות — Google People + AI Guidebook
• כלי עבודה לבדיקת חוויית משתמש במוצרי AI, כולל שאלונים וצ'קליסטים — Microsoft HAX Toolkit
• מחקרים ומאמרים על שימושיות AI, מבוססי מחקר משתמשים — NN/g – Using AI for UX Work
מחקרים:
מנהלים רואים בשקיפות, בקרה ומסגרות של אחריות תנאי למיצוי הערך העסקי של AI, ולא רק חובה רגולטורית — סקרים עדכניים של PwC על Responsible AI
נייר מחקר שמדגיש שאלות של אמון, שקיפות ו‑over‑reliance, בדיוק הבעיות שדפוסים כמו חשיפת reasoning, אינדיקטורים לביטחון ו‑Human Escalation נועדו לפתור — NN/g — Generative AI ב‑UX
ניסוי עם 404 משתתפים שהראה שביטויים בגוף ראשון של חוסר ודאות מפחיתים הסכמה עיוורת עם ה‑AI ומשפרים את השיפוט המשותף אדם+מודל — מחקר LLM uncertainty (2024)